
C#で音声ファイルから文字起こし(Azure、プロキシ、時刻出力、一括、SpeechToText)
目次
はじめに

こんにちは、のんびりエンジニアのたっつーです。
Twitter(@kingyo222)で Unity情報 を発信しているのでよければフォローしてください!
最近は、音声ファイルから文字起こし(Speech to Text)をする機会が多かったので、Azureを使ったサンプルソースコードをご紹介させていただきます。
使い方
Azure Speech Service で キー/リージョン を取得
まずは、Azure クラウドを使用するので、
Azure Portal で Speech Services を作成して、Key / Region を取得します。
Region はこちらから正確な値を取得してください。

例)
const string KEY = “32文字の英数字”;
const string REGION = “japaneast”;
プロジェクトの作成
Visual Studio 2019 で、新規で「コンソールアプリ(.NET Framework)」を選択して、「SpeechToTextSample」でプロジェクトを作成します。
※プロジェクト名は任意です。

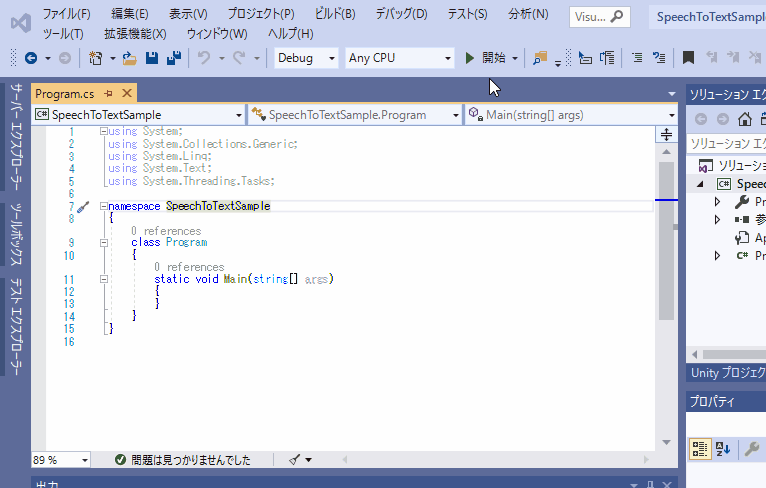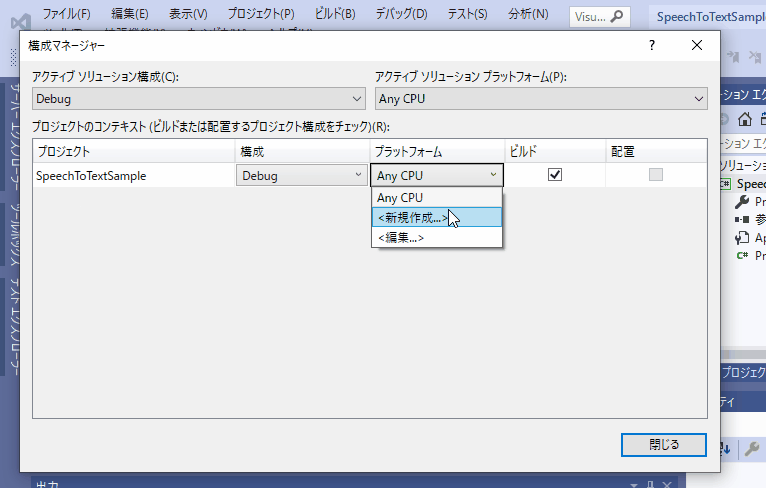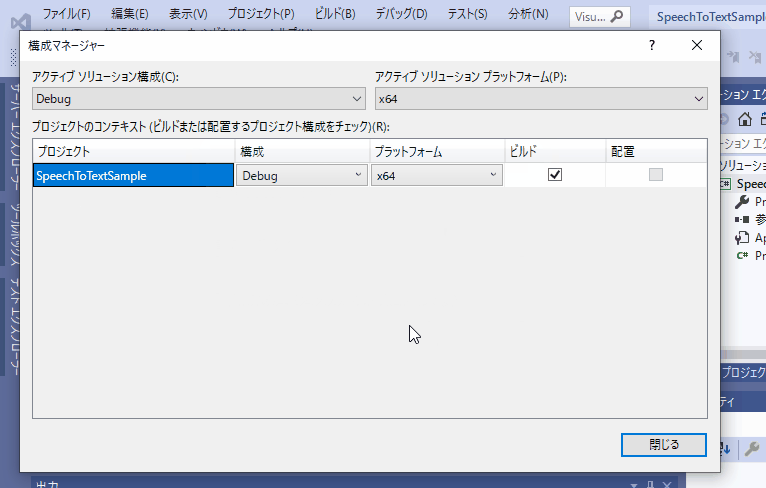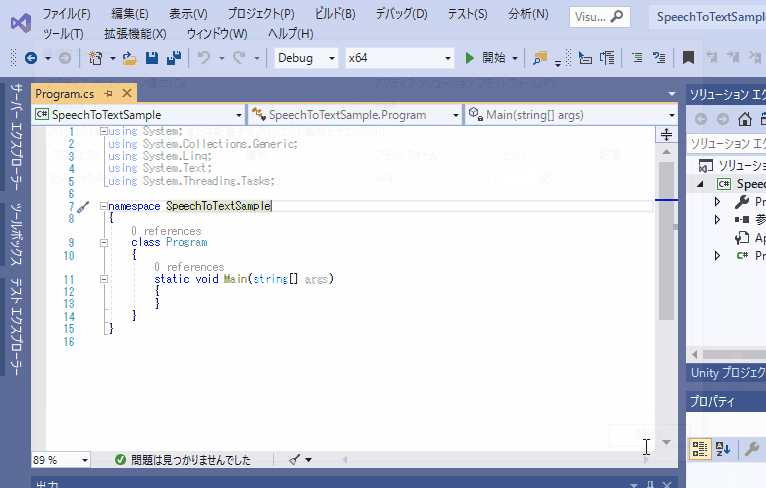
デバッグ構成の変更
今回は、「Microsoft.CognitiveServices.Speech」のライブラリを使うのですが、このライブラリを使う時には、デバッグ構成「Any CPU」だとうまく動かないので、x64/x84 にする。CPUアーキテクチャを変更しておきましょう。
64bit環境→x64
32bit環境→x84
Azure Speech ライブラリを追加
Azure Speechサービスを、C#で使えるようにライブラリを追加します。
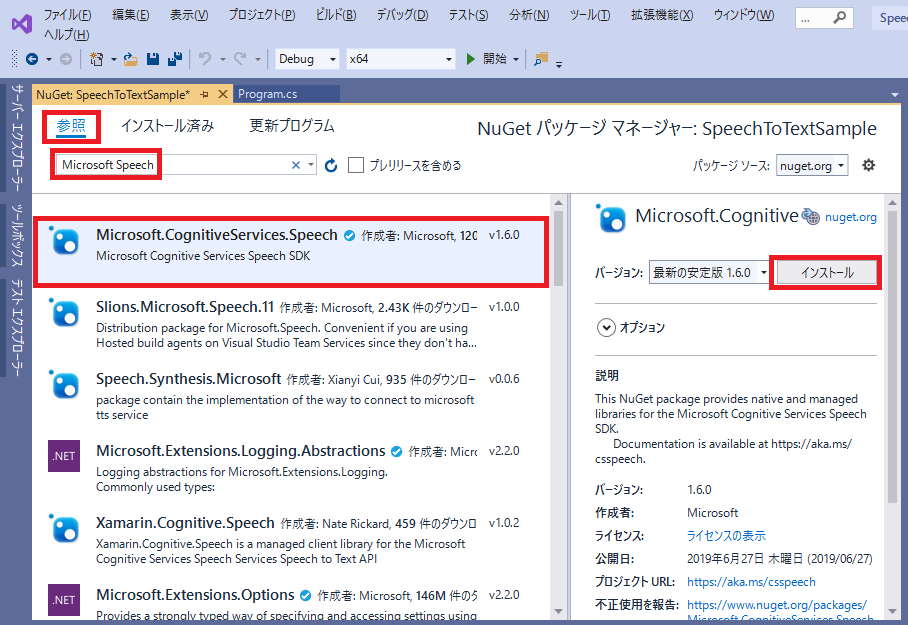
メニューから、「ツール > NuGet パッケージマネージャー > ソリューションのNuGetパッケージ管理」でNuGet管理マネージャーを起動してください。
次に、「Microsoft Speech」で検索を行い、「Micorosoft.Cognitive.Services.Speech」ライブラリをインストールしてください。
ソースコードの追加
次に、Azure にアクセスして、SpeechToTextを実行してくれるクラス、「AzureSpeechToText.cs」でソースコードを追加してください。
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
using System;
using System.Text;
using System.Threading.Tasks;
namespace SpeechToTextSample
{
public class AzureSpeechToText
{
const string KEY = "32文字の英数字";
const string REGION = "japaneast";
const string LOCALE = "ja-JP";
const string PROXY_HOST = "";
const int PROXY_PORT = 0;
public async Task<string> RecognizeAsync(string wavefile)
{
// Console.WriteLine($"RecognizeAsync: waveFile={wavefile}");
// Azure情報の設定
var config = SpeechConfig.FromSubscription(KEY, REGION);
config.SpeechRecognitionLanguage = LOCALE;
// Proxyの設定
if (!string.IsNullOrEmpty(PROXY_HOST))
config.SetProxy(PROXY_HOST, PROXY_PORT);
// 文字起こし開始
var result = await RecognizeStartAsync(config, wavefile);
return result;
}
private async Task<string> RecognizeStartAsync(SpeechConfig config, string wavefile)
{
var sb = new StringBuilder();
var stopRecognition = new TaskCompletionSource<int>();
// SpeechToTextの開始
using (var audioInput = AudioConfig.FromWavFileInput(wavefile))
{
using (var recognizer = new SpeechRecognizer(config, audioInput))
{
// recognizer.Recognizing += (s, e) =>
// {
// Console.WriteLine($"RECOGNIZING: Text={e.Result.Text}");
// };
recognizer.Recognized += (s, e) =>
{
if (e.Result.Reason == ResultReason.RecognizedSpeech)
{
var time = TimeSpan.FromSeconds(e.Result.OffsetInTicks / 10000000).ToString(@"hh\:mm\:ss");
var text = $"{time} {e.Result.Text}\n";
Console.Write(text);
sb.Append(text);
}
else if (e.Result.Reason == ResultReason.NoMatch)
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
}
};
recognizer.Canceled += (s, e) =>
{
// Console.WriteLine($"CANCELED: Reason={e.Reason}");
if (e.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={e.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={e.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
// ret = null;
}
stopRecognition.TrySetResult(0);
};
// recognizer.SessionStarted += (s, e) =>
// {
// Console.WriteLine("\n Session started event.");
// };
// recognizer.SessionStopped += (s, e) =>
// {
// Console.WriteLine("\n Session stopped event.");
// Console.WriteLine("\nStop recognition.");
// if (string.IsNullOrEmpty(ret))
// ret = "";
// stopRecognition.TrySetResult(0);
// };
// Starts continuous recognition. Uses StopContinuousRecognitionAsync() to stop recognition.
await recognizer.StartContinuousRecognitionAsync().ConfigureAwait(false);
// Waits for completion.
// Use Task.WaitAny to keep the task rooted.
Task.WaitAny(new[] { stopRecognition.Task });
// Stops recognition.
await recognizer.StopContinuousRecognitionAsync().ConfigureAwait(false);
}
}
return sb.ToString();
}
}
}
パラメータの変更
該当ソースコードの、以下パラメータをご自分の環境に従って変更してください。
- KEY : Azure Speechサービスで取得した、Keyを設定
- REGION : Azure Speechサービスで取得した、Regionを設定
(Regionはどこの地域のサーバーかを設定します) - LOCALE : 文字起こしする言語の設定
- PROXY_HOST : プロキシサーバーを挟んでいる場合は、そのホスト
- PROXY_PORT : プロキシサーバーを挟んでいる場合は、そのポート
const string KEY = "32文字の英数字";
const string REGION = "japaneast";
const string LOCALE = "ja-JP";
const string PROXY_HOST = "";
const int PROXY_PORT = 0;使い方
次に、Programクラスの Main関数を以下のように変更します。
※ Main関数を「async Task」に変更するのを忘れないように!
プログラムの概要としては、「C:\temp」にある 「~.wav」を取得して、「~.wav.txt」を出力するようなプログラムになります。
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
namespace SpeechToTextSample
{
class Program
{
static async Task Main(string[] args)
{
var dir = @"C:\temp";
var speechToText = new AzureSpeechToText();
// ファイル一覧の取得
var files = new List<string>();
files.AddRange(Directory.GetFiles(dir, "*.wav"));
// テキスト変換の開始
foreach (var file in files)
{
Console.WriteLine("--------------------------");
Console.WriteLine(file + " ... ");
var result = await speechToText.RecognizeAsync(file);
File.WriteAllText(file + ".txt", result);
Console.WriteLine(file + " ... end");
Console.WriteLine("");
Console.WriteLine("");
Console.WriteLine("");
}
}
}
}
実行結果
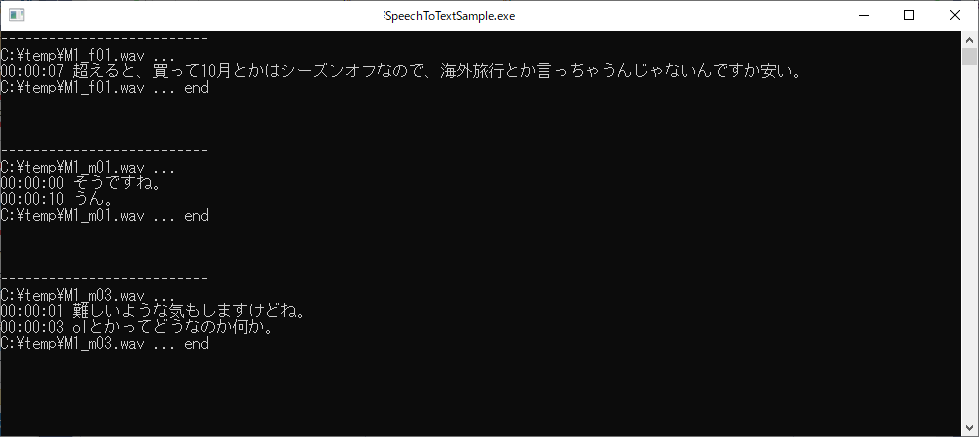
今回は、このサイトから音声サンプルをお借りしてみましたので、気になる方は試してみてください。
実際に実行してみると、正常に変換がされている事が確認できました。
一部変換ミスが見られますが、クラウドサービスの品質が改善するのを期待したいところです。
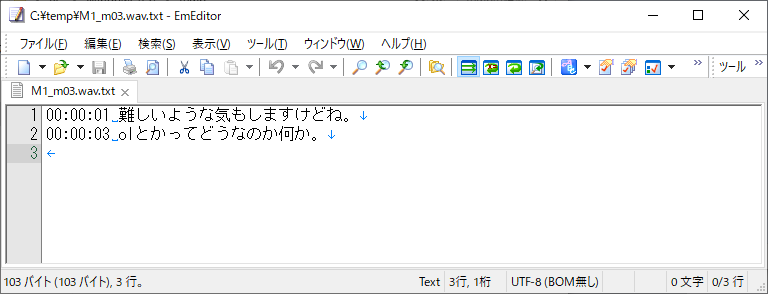
ついでに、wav毎に、テキスト変換したファイルも出力されます。
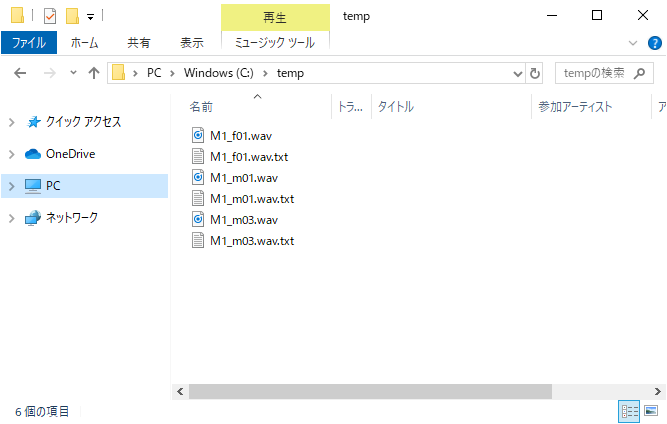
ファイルの中身は、こんな感じになります。
当該.wavファイルの、時刻(時分秒) と変換されたテキストが対になって出力されます。
よければ、SNSにシェアをお願いします!